Machine Learning#
from cider.datastore import DataStore
from cider.ml import Learner
Initialize data store object, then learner, automatically loading feature file produced by featurizer, along with file of data labels, and merging features to labels.
# This path should point to your cider installation, where configs and data for this demo are located.
from pathlib import Path
cider_installation_directory = Path('../../cider')
datastore = DataStore(config_file_path_string= cider_installation_directory / 'configs' / 'config_quickstart.yml')
learner = Learner(datastore=datastore, clean_folders=True)
Number of observations with features: 1000 (1000 unique)
Number of observations with labels: 50 (50 unique)
Number of matched observations: 50 (50 unique)
Experiment quickly with untuned models to get a sense of accuracy. Lasso, Ridge, random forest, and gradient boosting models are implemented natively, other models can be implemented by hand.
lasso_scores = learner.untuned_model('lasso')
randomforest_scores = learner.untuned_model('randomforest')
print('LASSO', lasso_scores)
print('Random Forest', randomforest_scores)
LASSO {'train_r2': '1.00 (0.00)', 'test_r2': '-0.19 (0.48)', 'train_rmse': '6.65 (-3.02)', 'test_rmse': '15665.32 (-1859.46)'}
Random Forest {'train_r2': '0.84 (0.01)', 'test_r2': '-0.02 (0.12)', 'train_rmse': '6200.40 (-319.50)', 'test_rmse': '14937.78 (-1482.62)'}
Fine-tune a gradient boosting model, tuning hyperparameters over cross validation, and produce predictions for all labeled observations out-of-sample over cross-validation. Also generate predictions for all subscribers in the feature dataset.
gradientboosting_scores = learner.tuned_model('gradientboosting')
print('Gradient Boosting (Tuned)', gradientboosting_scores)
learner.oos_predictions('gradientboosting', kind='tuned')
learner.population_predictions('gradientboosting', kind='tuned')
[LightGBM] [Warning] min_data_in_leaf is set=10, min_child_samples=20 will be ignored. Current value: min_data_in_leaf=10
Gradient Boosting (Tuned) {'train_r2': '0.80 (0.03)', 'test_r2': '0.07 (0.12)', 'train_rmse': '6808.46 (-409.84)', 'test_rmse': '14259.12 (-1920.92)'}
[LightGBM] [Warning] min_data_in_leaf is set=10, min_child_samples=20 will be ignored. Current value: min_data_in_leaf=10
[LightGBM] [Warning] min_data_in_leaf is set=10, min_child_samples=20 will be ignored. Current value: min_data_in_leaf=10
[LightGBM] [Warning] min_data_in_leaf is set=10, min_child_samples=20 will be ignored. Current value: min_data_in_leaf=10
[LightGBM] [Warning] min_data_in_leaf is set=10, min_child_samples=20 will be ignored. Current value: min_data_in_leaf=10
| name | predicted | |
|---|---|---|
| 0 | dsBHAdXrrk | 67249.768675 |
| 1 | JGPCbfDGes | 69289.940765 |
| 2 | dYwshzRseD | 85109.109600 |
| 3 | ygMEXUQDbn | 82018.137664 |
| 4 | YtvkGlMWwe | 76983.875546 |
| ... | ... | ... |
| 5 | amzyXHglBx | 83987.844414 |
| 6 | zZkqaZFAtz | 82984.849245 |
| 7 | uXZrufHOmE | 87731.514440 |
| 8 | dJSvXqUVSY | 76191.160752 |
| 9 | YosNCLWrFL | 85338.034626 |
1000 rows × 2 columns
Evaluate the model’s accuracy. Produce a scatterplot of true vs. predicted values with a LOESS fit and a bar plot of the most important features. Generate a table showing the targeting accuracy, precision, and recall of the predictions for nine hypothetical targeting scenarios (targeting between 10% and 90% of the population).
learner.scatter_plot('gradientboosting', kind='tuned')
learner.feature_importances_plot('gradientboosting', kind='tuned')
learner.targeting_table('gradientboosting', kind='tuned')
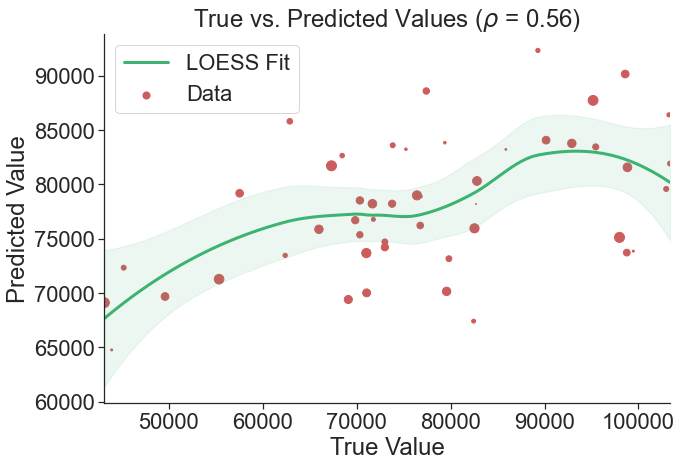
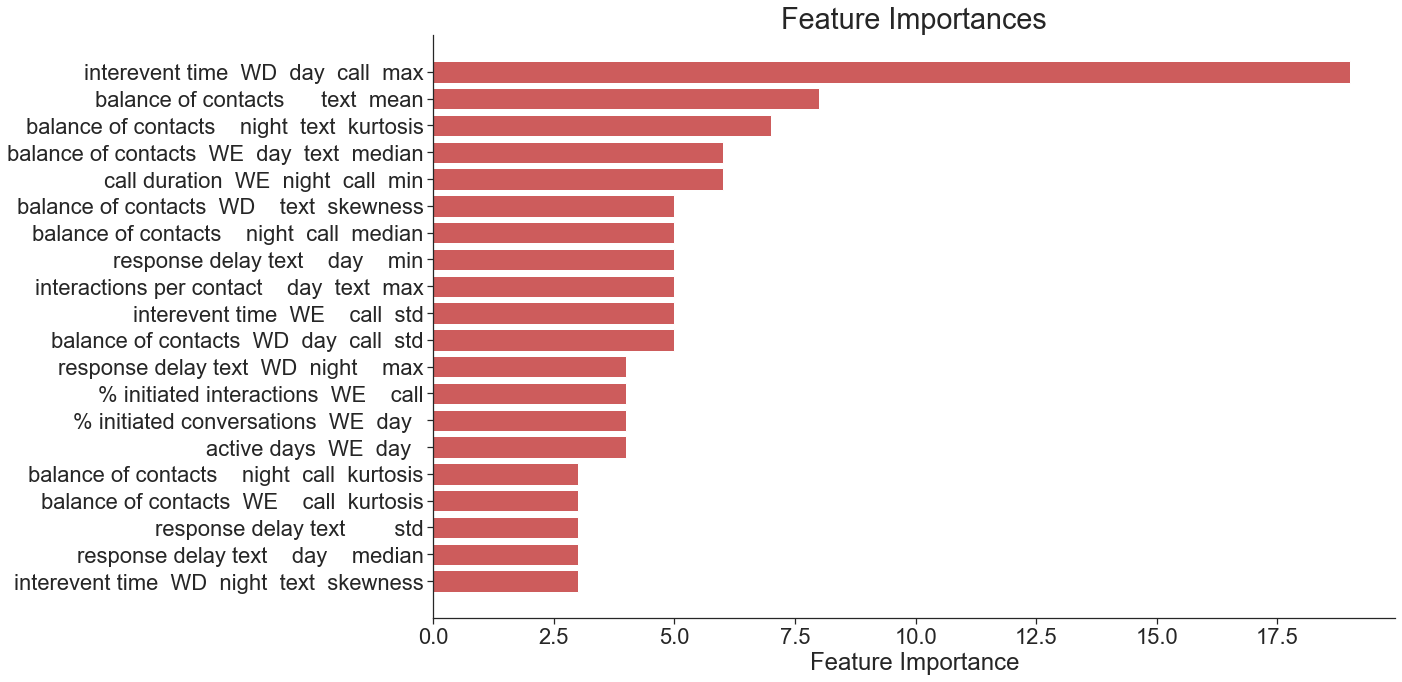
| Proportion of Population Targeted | Pearson | Spearman | AUC | Accuracy | Precision | Recall | |
|---|---|---|---|---|---|---|---|
| 0 | 10% | 0.56 | 0.5 | 0.73 | 93% | 65% | 65% |
| 1 | 20% | 0.56 | 0.5 | 0.73 | 81% | 53% | 53% |
| 2 | 30% | 0.56 | 0.5 | 0.73 | 71% | 52% | 52% |
| 3 | 40% | 0.56 | 0.5 | 0.73 | 67% | 59% | 59% |
| 4 | 50% | 0.56 | 0.5 | 0.73 | 65% | 65% | 65% |
| 5 | 60% | 0.56 | 0.5 | 0.73 | 69% | 74% | 74% |
| 6 | 70% | 0.56 | 0.5 | 0.73 | 79% | 85% | 85% |
| 7 | 80% | 0.56 | 0.5 | 0.73 | 75% | 84% | 84% |
| 8 | 90% | 0.56 | 0.5 | 0.73 | 84% | 91% | 91% |