Fairness Evaluations#
from cider.datastore import DataStore
from cider.fairness import Fairness
Set up the configuration file and load some fairness simulation data, using the datastore.
# This path should point to your cider installation, where configs and data for this demo are located.
from pathlib import Path
cider_installation_directory = Path('../../cider')
datastore = DataStore(config_file_path_string= cider_installation_directory / 'configs' / 'config_quickstart.yml')
fairness = Fairness(datastore=datastore)
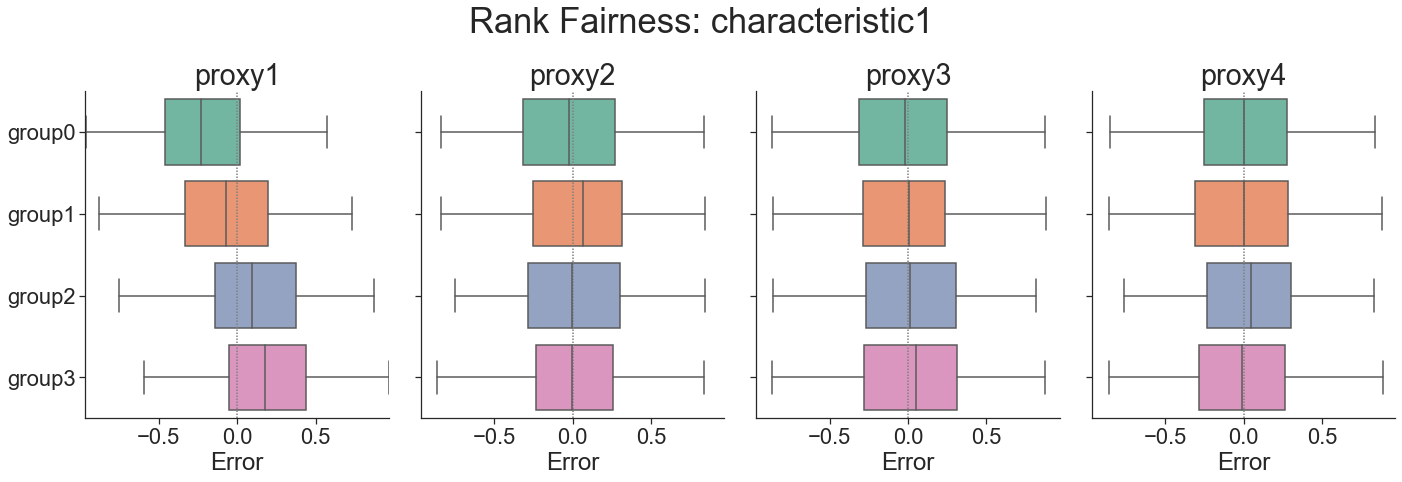
Create a “rank residuals boxplot”. Provide (1) a ground-truth poverty measure, (2) a set of proxy poverty measures that could be used for targeting, and (3) a characteristic of interest to evaluate fairness across (the characteristic must take on at least two distinct values that appear in the dataset). The “rank residual” for each observation will be calculated: the difference between the ranking of that observation according to the proxy and according to the ground truth. We then visualize the distribution of rank residuals for each group; if proxy measures are fair targeting methods the mean of all distributions should be close to 0.
fairness.rank_residuals_plot('consumption', ['proxy1', 'proxy2', 'proxy3', 'proxy4'], 'characteristic1')
To test the statistical significance of the difference in means for each proxy, use an ANOVA test. Results are presented in a table that records the mean and standard deviation of rank residuals by proxy and group, and the ANOVA test for the difference in means between groups. Look for large F statistics and p-values less than 0.05.
fairness.rank_residuals_table('consumption', ['proxy1', 'proxy2', 'proxy3', 'proxy4'], 'characteristic1')
| characteristic1 | proxy1 | proxy2 | proxy3 | proxy4 | |
|---|---|---|---|---|---|
| 0 | group0 | -0.21 (0.36) | -0.02 (0.38) | -0.03 (0.39) | -0.01 (0.37) |
| 1 | group1 | -0.07 (0.37) | 0.02 (0.38) | -0.02 (0.37) | -0.01 (0.40) |
| 2 | group2 | 0.11 (0.37) | -0.00 (0.38) | 0.02 (0.37) | 0.03 (0.37) |
| 3 | group3 | 0.19 (0.35) | -0.00 (0.36) | 0.03 (0.39) | -0.01 (0.40) |
| 4 | Anova F-Stat | 61.1195 | 0.598312 | 1.36395 | 0.806921 |
| 5 | Anova p-value | 2.83854e-36 | 0.616193 | 0.252376 | 0.4901 |
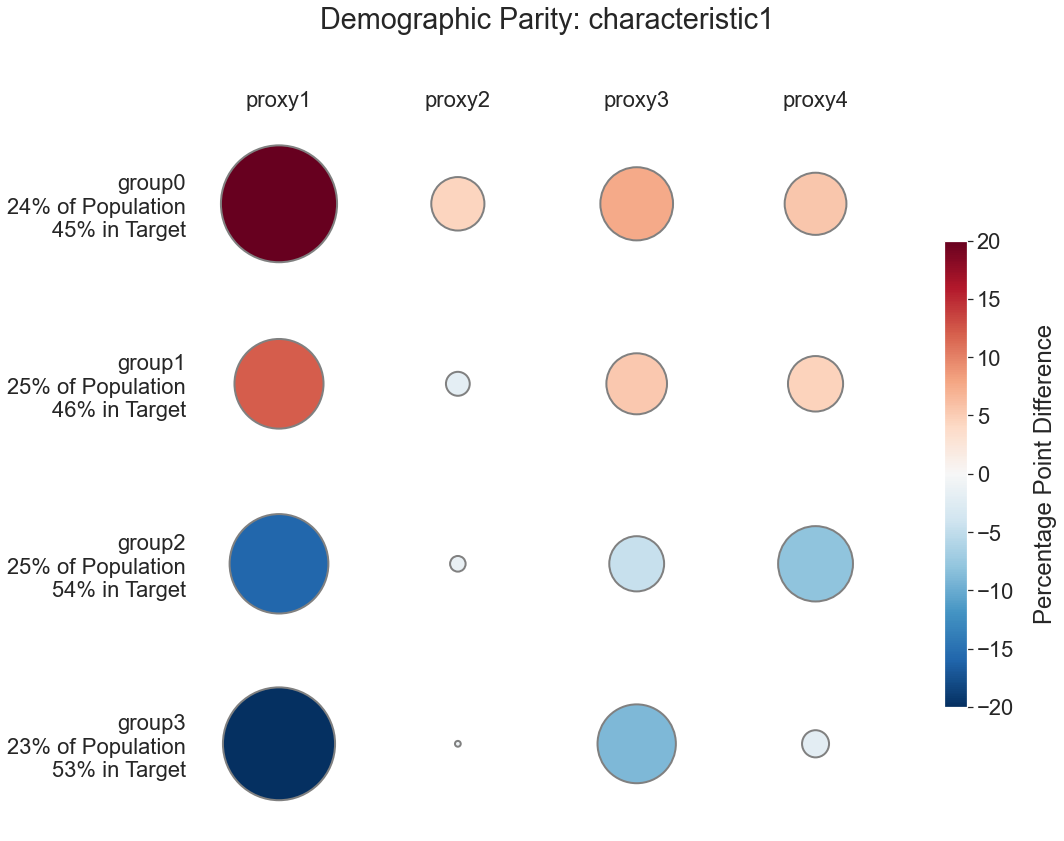
Provide a targeting threshold (in percentile) to calculate demographic parity: the difference between the share of a group that is targeted according to each proxy measure and the share of the group that is targeted according to the ground-truth proxy measure. Differences are provided as percentage points.
fairness.demographic_parity_table('consumption', ['proxy1', 'proxy2', 'proxy3', 'proxy4'], 'characteristic1', 50)
| characteristic1 | Group's share of population | Share of Group in Target Population | proxy1 | proxy2 | proxy3 | proxy4 | |
|---|---|---|---|---|---|---|---|
| 0 | group0 | 24.90% | 45.38% | 25.702811 | 4.417671 | 7.630522 | 5.622490 |
| 1 | group1 | 25.70% | 46.69% | 12.062257 | -1.945525 | 5.447471 | 4.669261 |
| 2 | group2 | 25.90% | 54.44% | -15.830116 | -1.544402 | -4.633205 | -8.108108 |
| 3 | group3 | 23.50% | 53.62% | -22.978723 | -0.851064 | -8.936170 | -2.127660 |
Visualize the above table as a heatmap with bubbles.
fairness.demographic_parity_plot('consumption', ['proxy1', 'proxy2', 'proxy3', 'proxy4'], 'characteristic1', 50)